Le développement exponentiel du marché de la vidéo en ligne entraîne l’émergence de nouveaux services à la demande en France et dans le monde (récemment Zive, Molotov TV ou encore Amazon Instant Video, Youtube Red, etc). L’offre est vaste : films, séries mais aussi programmes de flux, émissions, sports… et s’enrichit en permanence avec des contenus exclusifs. Les plateformes OTT, les réseaux multi-chaînes (MCN), les chaînes de télévision et les acteurs du monde audiovisuel ont un besoin croissant en données d’identification et de description des programmes.
L’enjeu est double, d’abord pour les diffuseurs qui souhaitent proposer la meilleure expérience à leurs utilisateurs et ont besoin de données pour rechercher, enrichir et recommander les contenus, ainsi que pour les ayants droit et leurs représentants qui doivent suivre l’exploitation de leurs œuvres sur les différents canaux.
Les métadonnées relatives aux contenus, mises en lien avec les données de consommation sont essentielles au bon fonctionnement et au développement des offres en ligne et se trouvent au cœur de la compétition entre les acteurs.
Utiliser des données pour en décrire d’autres
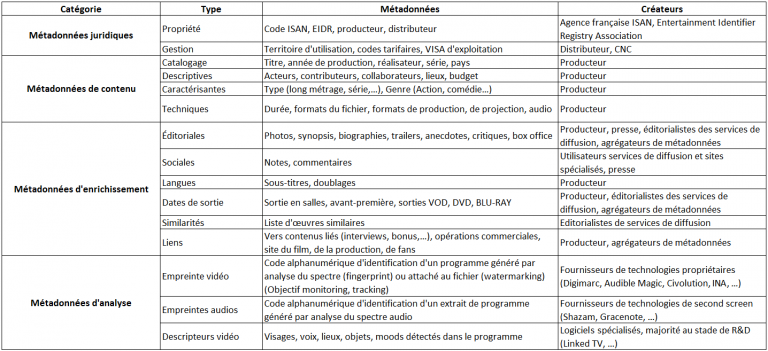
Les métadonnées sont définies comme des « données relatives à des données » et utilisées pour identifier (métadonnées de propriété), gérer (métadonnées de gestion de droits), qualifier et rechercher (métadonnées de description) ainsi qu’enrichir les contenus.
Créées par les producteurs et éditeurs du contenu ou de manière collaborative, elles peuvent aussi être issues directement de l’analyse automatique du signal. Les métadonnées sont soit intégrées au fichier transportant les données multimédia soit transportées dans des formats d’échange annexes.
Classification des métadonnées.
Proposer les meilleurs services aux utilisateurs
Les métadonnées vont avoir plusieurs rôles et leurs usages sont stratégiques :
- Identifier les œuvres et les ayant-droits pour bien répartir les revenus.
- Enrichir le service en proposant des informations précises et complètes aux utilisateurs sur les programmes, les animateurs, les acteurs, des anecdotes, …
- Rechercher et trouver les contenus facilement en ajoutant des tags de description et en proposant des champs de recherche avancée (date, genre, acteur, durée, …).
- Référencer et optimiser le SEO sur les moteurs de recherche en ajoutant des balises et mots-clés. Suggérer des contenus similaires en créant des liens entre les champs de description.
- Recommander des contenus aux utilisateurs en les croisant aux données de consommation. Plus il y aura de tags plus les recommandations pourront être personnalisées et variées.
- Développer des expériences interactives en liant des contenus externes aux données du programme.
Les métadonnées de description et d’enrichissement constituent un enjeu hautement concurrentiel pour les diffuseurs.
Depuis les années 1980 des bases de données sont enrichies et mises à disposition des diffuseurs (chaînes de télévision, acteurs de l’audiovisuel et ultérieurement les plateformes de VàD et SVàD). Ces bases peuvent être de différents types : ouvertes car enrichies de manière collaborative par les utilisateurs (Imdb, TVdb, Wikipedia, Freebase etc.), payantes car développées par des sociétés qui créent, agrègent, traitent et diffusent ces données (Rovi, Gracenote, CBS, Plurimedia…) ou publiques en ce qui concerne les codes et visa d’exploitation (bases ISAN, EIRA dont les identifiants sont disponibles dans les bases des sociétés de gestion collective). De même les bases de données spécialisées de critiques, notes et commentaires comme Amazon ou Rotten Tomatoes se révèlent très utiles pour enrichir les services. D’autres types de bases spécialisées dans les données de programmes sportifs deviennent des acteurs importants : Sportsdatabase, the Sports Standards Alliance...
Ces sociétés peu connues du grand public - mais fournisseurs de la plupart des services proposés par les plateformes numériques et les opérateurs télécoms - ont fait, au niveau international, l’objet de nombreuses opérations financières ces dernières années. Pour exemple Rovi Corporation a acquis All Media Network (Allmovie, All Music), Gracenote, une filiale du groupe Tribune Media (qui l’avait racheté à Sony) a acheté Baseline, Red Bee est devenue la propriété d’Ericsson Broadcast Media, et Metacritic celle de CBS.
Rovi propose 7 millions de contenus décrits aussi divers que des films, des programmes TV ou des retransmissions d’évènements sportifs internationaux et fournit notamment Google, Netflix et Facebook. Gracenote propose 6 millions de contenus et travaille quant à elle pour HBO, Syfy, Roku, Sony ou Philips. La France n’est pas en reste avec des services comme Plurimédia, Unifrance, Senscritique ou Cinémur qui fournissent des descriptions, critiques et guides pour les diffuseurs. Une plateforme comme Allociné détient quant à elle une base d’informations extrêmement complète et donc potentiellement très valorisable.
Améliorer la gestion des métadonnées pour garantir la rémunération des ayants droits
Au-delà de leur rôle d’enrichissement des services de diffusion les métadonnées sont nécessaires à l’identification des programmes et donc à la rémunération de leurs ayant droits.
Les métadonnées dites juridiques attachées au fichier permettent d’identifier le fichier : ainsi reconnues par les systèmes à tous les niveaux de sa diffusion, il devient possible de tracer l’œuvre et donc de répartir justement les revenus issus de l’exploitation des œuvres. Pour permettre une identification universelle des métadonnées, des standards internationaux ont été définis : les codes ISAN et ISNI pour les contenus, l’ISI et l’IPI pour les contributeurs. L’ISAN, un code généré à la demande des producteurs est globalement adopté, il est stocké dans les bases des sociétés de gestion collective.
Cependant, bien que ces standards aient été créés et soient reconnus au niveau international, des difficultés subsistent. L’étude commandée par le Ministère de la Culture à la suite de la Mission Lescure, menée par le cabinet BearingPoint auprès des acteurs du secteur audiovisuel français et rendue publique en juillet 2015, identifie trois dysfonctionnements majeurs des métadonnées :
- L’utilisation des standards n’est pas généralisée : « les diffuseurs utilisent au contraire leurs propres identifiants internes pour référencer leurs contenus et les identifiants normalisés des contributeurs ne sont pas non plus utilisés ». Les acteurs interrogés dans le cadre de l’étude avancent l’argument de « la complexité de l’intégration des identifiants normalisés dans leurs systèmes de diffusion » ainsi que « la difficulté de définir des modalités d’identification pertinentes [tant] les contenus audiovisuels sont variés et peuvent être exploités sous des formes très différentes ». En effet les contenus télévisuels (reportages, émissions, lives…) peuvent être mis en ligne sous différentes formes et unévènement unique filmé de différentes façons n’est plus considéré comme étant le même objet. Dans ce cas les pratiques diffèrent, certaines chaînes attribuent plusieurs identifiants à un même contenu en fonction du mode de diffusion et elles ne réutilisent pas systématiquement ces identifiants en cas de rediffusion, rendant ainsi le traçage impossible.
- La qualité des champs de métadonnées n’est pas satisfaisante : à l’instar de l’industrie musicale où Last.fm avait identifié 56 manières d’écrire le nom du groupe Guns N’Roses certains noms sont par exemple mal orthographiés et l’utilisation de référentiels différents par les acteurs de la filière rend nécessaire la création de tables de correspondance. Ce phénomène est d’autant plus important avec la graphie des noms étrangers. L’étude précise encore qu’il arrive que « certains éditeurs de contenus diffusés sur les plateformes de VàD ou sVàD puissent renseigner des métadonnées incorrectes de manière intentionnelle, à l’instar de la date de parution, afin d’optimiser le positionnement de leurs contenus. Le plus souvent, les diffuseurs acceptent les métadonnées en l’état afin de préserver leurs intérêts commerciaux ».
Last.fm a identifié 56 manières d’écrire le nom du groupe Guns N’Roses
- L’absence d’une base ouverte (publique) répertoriant les ayants droit : il manque aujourd’hui « un guichet permettant de donner à toute personne morale ou physique souhaitant exploiter un contenu, les informations nécessaires pour pouvoir le faire dans un cadre légal ». Les sociétés comme Rovi, Gracenote ou la base de Content ID de YouTube pourraient constituer demain des registres de référence pour identifier les droits et ayant droits au risque de porter atteinte à la souveraineté culturelle française. Les acteurs achètent donc les données aux bases comme Plurimédia et le coût pour la filière est estimé annuellement entre 6 et 13 millions d’euros.
Pour remédier à ces problèmes, l’étude propose plusieurs solutions. D’abord la solution avancée par la mission Lescure pensée dans le secteur musical et testée sans succès avec l’échec du GRD, à savoir la mise en place d’une base ouverte de métadonnées. Elle donne l’exemple du répertoire Balzac de la SGDL et propose d’y d’adjoindre un outil de génération d’empreintes numériques comme l’outil Signatures de l’INA afin de pouvoir lier des métadonnées d’identification à une empreinte unique. Cependant le coût estimé, les contraintes légales et la nécessité d’une coopération des acteurs représentent des obstacles importants à la constitution de cette base publique ouverte.
Ensuite, l’étude propose d’obliger les acteurs à utiliser les identifiants normalisés internationaux afin « d’optimiser les échanges d’information entre les acteurs de la filière, en réduisant les ressources en charge du rapprochement manuel des bases et des relevés » et optimiser le fonctionnement interne de certains diffuseurs. L’obstacle serait alors technique au vu de la complexité pour les diffuseurs d’intégrer ces identifiants dans leurs systèmes.
L’étude suggère aussi de sanctionner les pratiques consistant à renseigner des métadonnées incorrectes afin d’optimiser le référencement des contenus et conseille d’instaurer un standard de référence en matière d’échange de données. Ainsi « certains acteurs utilisent aujourd’hui le format CableLabs pour les envois d’informations, d’autres utilisent le format développé par l’organisation DDEX pour la musique. L’utilisation généralisée d’un standard d’échange adapté permettrait de fluidifier la circulation des informations entre les acteurs et donc d’optimiser les processus opérationnels ».
Des usages innovants liés à l’exploitation des métadonnées
Au-delà de l’enrichissement et du suivi des œuvres, les métadonnées sont essentielles au développement d’expériences personnalisées notamment au travers de la recommandation et du second écran.
L’objectif de la recommandation est de proposer le bon contenu à la bonne personne au bon moment,« à l’heure du big data et des médias délinéarisés, la recommandation idéale est celle qui s’adresse à un individu unique, dans des circonstances et un contexte uniques ». Les métadonnées en sont la matière essentielle avec en toile de fond un triple enjeu : pour les entreprises qui souhaitent proposer le système de recommandation idéale, pour les ayant droits qui ont intérêt à ce que leurs œuvres soient le plus diffusées possibles ainsi que pour la diversité culturelle, avec la mise en avant des œuvres constitutives de la longue traîne. Des métadonnées bien renseignées permettent d’optimiser la recommandation personnalisée grâce au croisement avec les données utilisateurs, à l’aide d’algorithmes.
La seule mise à disposition d’un catalogue et d’un moteur de recherche ne suffit plus à convaincre un utilisateur de s’abonner
La recommandation algorithmique basée sur l’analyse et le traitement des données est complémentaire à la curation humaine faite par les équipes éditoriales des plateformes. En effet le volume des contenus disponibles augmentant de manière exponentielle, la recommandation humaine seule ne permettrait de mettre en avant qu’une partie minoritaire des catalogues.
Les bénéfices d’une bonne recommandation pour une plateforme sont multiples : fidélisation de l’utilisateur grâce à une expérience personnalisée (exemple des recommandations Spotify suite à l’intégration du moteur d’analyse de données de The Echonest), récurrence des visites grâce à la suggestion de contenus pertinents par des notifications et augmentation de la durée de visionnage par utilisateur. Cette personnalisation du service est un facteur majeur de différenciation avec la concurrence : la seule mise à disposition d’un catalogue et d’un moteur de recherche ne suffit plus à convaincre un utilisateur de s’abonner ou à rester abonné et, à catalogue égal, la qualité du service proposé sera décisive.
Netflix par exemple investit plus de 150 millions de dollars chaque année dans le développement de son moteur de recommandation et ferait travailler 900 ingénieurs sur ses algorithmes.
Illustration schématique d’un moteur de recommandation :
Plusieurs sociétés et startups innovantes proposent des solutions de recommandation vidéo, en France, la start-up Cognik travaille notamment pour France Télévisions, Cisco ou Viacom tandis que Canalplay développe son propre moteur Eurêka, à l’instar de 6play, le service de M6.
Ces usages innovants créent un marché émergent qui se développe autour du second écran et des expériences interactives.
Dans le secteur musical, des technologies d’extraction automatique de données audio sont déjà déployées et des startups (Simbals, Niland, Musicovery, Musimap), des plateformes de streaming musical (Deezer, Spotify) et des organismes de recherche (l’Ircam, le Fraunhofer Institut, le Queen Mary) proposent à leurs clients des programmes d’enrichissement et de recommandation automatique des morceaux. De fait la recommandation de contenus liés se fait aujourd’hui à partir de la reconnaissance d’extraits audio et ce procédé est utilisé assez largement pour proposer des expériences avec le second écran, comme Shazam autour de publicités.
Pour la vidéo, des programmes de recherche publics (LinkedTV) et des entreprises innovantes (notamment Gracenote ou Shazam) travaillent aujourd’hui sur des technologies de description du signal vidéo afin d’extraire sans intervention humaine des données de films, séries et programmes de flux.
À la différence des logiciels de post production type Final Cut qui peuvent reconnaître des éléments dans une vidéo en montage ce procédé n’est pas applicable sur des vidéos éditées et diffusées.
Une fois matures, ces technologies pourraient ouvrir de nouvelles perspectives dans la recommandation et l’enrichissement des programmes. Le but est de qualifier les vidéos, très rapidement et précisément sans intervention humaine afin de mieux les référencer et les recommander (genre, acteurs, lieux, langues, etc.). Des expériences interactives deviendraient alors possibles, et la reconnaissance du visage d’un présentateur ou d’un objet pourrait mener automatiquement à des contenus liés ou des sites d’achat.
Les métadonnées sont donc au cœur des systèmes de diffusion des vidéos en ligne, en offrant la possibilité aux acteurs de développer des services enrichis en informations, mais aussi aux ayants droit de suivre l’exploitation des œuvres et pour les utilisateurs de profiter d’expériences personnalisées et innovantes. Cependant plusieurs défis d’ordre technique, technologique et juridique sont encore à relever pour optimiser le système et la « guerre des données » entre les acteurs ne fait que commencer… Aujourd’hui les arbitres sont les bases de données privées qui détiennent les informations, mais les pouvoirs publics ont la possibilité d’ouvrir une base ouverte de référence à destination de l’industrie, afin de changer la donne.
--
Illustration : Alice Durand